对数据进行聚类分析实验报告

对数据进行聚类分析实验报告
一、基本要求
用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C均值和分级聚类方法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。
二、实验要求
1、把FAMALE.TXT和MALE.TXT两个文件合并成一个,同时采用身高
和体重数据作为特征,设类别数为2,利用C均值聚类方法对数据进
行聚类,并将聚类结果表示在二维平面上。尝试不同初始值对此数据
集是否会造成不同的结果。
2、对1中的数据利用C均值聚类方法分别进行两类、三类、四类、五类
聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出
合理的类别数目。
3、对1中的数据利用分级聚类方法进行聚类,分析聚类结果,体会分级
聚类方法。。
4、利用test2.txt数据或者把test2.txt的数据与上述1中的数据合并在一
起,重复上述实验,考察结果是否有变化,对观察到的现象进行分析,
写出体会
三、实验步骤及流程图
根据以上实验要求,本次试验我们将分为两组:一、首先对FEMALE 与MALE中数据组成的样本按照上面要求用C均值法进行聚类分析,然后对FEMALE、MALE、test2中数据组成的样本集用C均值法进行聚类分析,比较二者结果。二、将上述两个样本用分即聚类方法进行聚类,观察聚类结果。并将两种聚类结果进行比较。
一、(1)、C均值算法思想
C均值算法首先取定C个类别和选取C个初始聚类中心,按最小距离原则将各模式分配到C类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各模式到其判属类别中心的距离平方之和最小
(2)、实验步骤
第一步:确定类别数C,并选择C个初始聚类中心。本次试验,我们分别将C的值取为2和3。用的是凭经验选择代表点的方法。比如:在样本数为N时,分为
两类时,取第1个点和第()1
INT个点作为代表点;分为三类时,取第1、
N
/+
2
()1
3/+
N
INT、()1
3/
2+
N
INT个点作为代表点;
第二步:将待聚类的样本集中的样本逐个按最小距离规则分划给C个类中的某一类。
第三步:计算重新聚类后的个各类心,即各类的均值向量。
第四步:如果重新得到的类别的类心与上一次迭代的类心相等,则结束迭代,否则转至第二步。
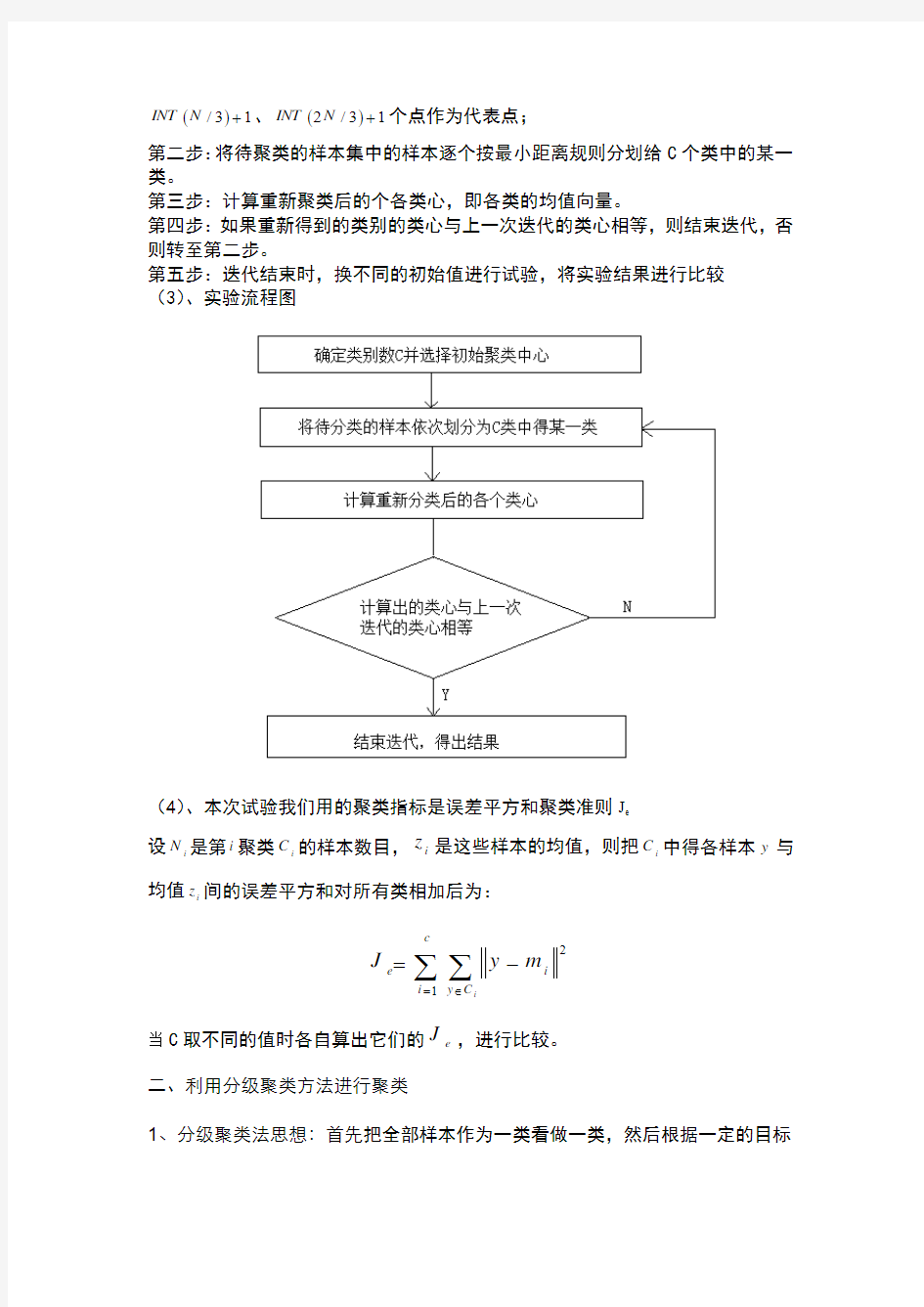
第五步:迭代结束时,换不同的初始值进行试验,将实验结果进行比较(3)、实验流程图
(4)、本次试验我们用的聚类指标是误差平方和聚类准则J
e
设
i
N是第i聚类i C的样本数目,i z是这些样本的均值,则把i C中得各样本y与
均值
i
z间的误差平方和对所有类相加后为:
∑∑=∈-
=
c
i C
y i
e
i
m y
J
1
2
当C取不同的值时各自算出它们的e
J,进行比较。
二、利用分级聚类方法进行聚类
1、分级聚类法思想:首先把全部样本作为一类看做一类,然后根据一定的目标
函数进行分解。 2、步骤
第一步:开始时,将全部样本当做一类,第二类即为空集。
第二步:将第一类中的所有样本依次放入第二类,计算两类样本均值1X , 2X ,样本数目1N ,2N 以及目标函数121212()'()N N E X X X X N
=
--,比较
E 值大小,选
择E 值最大所对应的样本,将其归入第二类。并记录此时的E 为E (1)
第三步:将第一类中剩下样本依次放入第二类中,按照上面运算得出E 值,并比较E 值大小,选择E 值最大所对应的样本,将其归入第二类。并记录此时的E 为E (2) 第三步:将新的两类按照上面的方法继续划分,直到第i 次迭代的E (i ) 四、 实验结果 I、1、用FAMALE.TXT和MALE.TXT中的数据组合起来作为样本集: C=2时 (1)、取第一个和第五十一个样本作为初始聚类中心,得出的实验结果图如下: 得到结果是:点号表示的类别中样本总数为61,星表示的类别中样本总数为39 。两个聚类中心分别为: A(163.5738,53.1541),B(175.8974,68.2692) 2)、取第二十五个和七十五个样本作为初始聚类中心时得到的实验结果如下: 得到结果是:点号表示的类别中样本总数为61,星表示的类别中样本总数为39。两个聚类中心分别为: A(163.5738,53.1541),B(175.8974,68.2692) 进行多次试验发现取不同的初始聚类中心时实验结果相同。 J=5.9707e+003 它们的e 但是,经过后面的实验我们发现,初始聚类中心选择影响最后的聚类中心,其能保证优化,而不能保证全局优化,ISODATA在这一点比C-均化更好。 下面是将男女样本所代表的点分别画到图上可得下图: 其中点表示的是女生样本,圆圈表示的是男生样本。其中,男生的样本均值为(173.9200 ,65.5020)女生的样本均值为(162.8400 ,52.5960) 通过比较两幅图,可以发现,当去C=2时,对数据进行聚类分析得到的聚类结果基本类似于男女生分类,他们的样本均值相差不大,不过还是有一定差别。差别出现在一些身高低于1.70米的男生处。 C=3时得到的聚类结果图如下: 最终的三个聚类中心: A(159.2333,49.9333)B(168.8158,57.0105)C(176.4375,70.0156)J=3.9251e+003 e 从图中可以看出,当划分为三类时,其结果可以看做按照身高与体重的比将样本进行聚类,身高体重比大,较大,小的分别为一类。 C=4时:得到的分来结果如下: 得到的四个聚类中心为: A(157.4286,49.2381),B(164.7727,53.3545)C(170.4400,58.2640),D(176.4375,70.0156)J=3.4318e+003 e C=5时得到的聚类结果如下: 最终的五个聚类中心分别为: A(158.1579,47.3684),B(163.3913,54.4652)C(170.3462,58.1423),D(176.0741,67.7593)E(178.4000,82.2000) J=2.6352e+003 e C=6时得到的聚类结果如下: 最终的6个聚类中心分别为: A(158.3462,49.8462)B(166.9259,54.5889)C(171.4737,60.8158)D(175.6842,68.1842)E(178.0000,80.6667)F(183.3333,66.6667)J= 2.5607e+003 e J之间的关系曲线如下: 1、画出C值与e 由图可以看出,拐点离2较近,所以讲此样本集聚为二类最佳 2、把test2.txt的数据与上述1中的数据合并在一起,重复上述实验,实验结果 如下: (1)、取第二十五个和第二百零一个个样本作为初始聚类中心,得出的实验结果图 其中,A(165.0479,53.6491),B(176.4506,69.9378) J=3.2952e+004 e 取第一百个和第三百个样本作为初始聚类中心时得出结果与前面相同。 (2)、C=3 A(163.3438,51.8742), B(174.5561,64.5024)C(178.8657 ,80.4776) J=2.0594e+004 e (3)、C=4时: J=1.6346e+004 e A(159.8548 ,48.3145),B(167.5567,56.6485)C(175.4783,65.7908),D(179.3684,81.7368) (4)C=5时: J=1.3575e+004 e A(160.5732,50.0512),B(170.0510,57.5020)C(175.3836 ,65.9452),D(178.6429,75.7589) E(179.6667,91.3889) (5)、C=6时 其中,e J= 1.3018e+004 A(160.8427,50.6596)B(170.6296,55.1241)C(172.6381,62.9143)D(176.8488,76.8837)E(177.2955,68.0057)F(181.5952,89.1905) J之间的关系曲线如下 画出C值与e 与图可知,拐点离2较近,所以认为此时仍是将样本集分为二类最佳 (4)、将两种样本即进行聚类后的样本中心进行比较,如下表: 他们的聚类中心也越接近。横向比较用FEMALE,MALE中数据作为样本和用FEMALE,MALE,test2中数据作为样本时,由于引入了新的样本,可以发现后者的聚类中心比前者都稍大。但是它们的分布类似,变化不大。 II、将两个样本分别用分级聚类方法进行聚类,得出结果,并与C均值聚类法进行比较: 1、对FEMALE与MALE中数据组成的样本集进行分级聚类: 由图可见,分级聚类法将样本分为两类,它们的聚类中心分别为 A(163.4667,53.0400)B(175.7500,68.0625) 将它与C=2时的C均值聚类结果进行比较,分别比较它们的结果图以及聚类中心,下面是它们的聚类中心比较: 2、对由MALE、MALE、test2中数据组成的样本集进行分级聚类: 由图可见,分级聚类法将样本分为两类,它们的聚类中心分别为 A(164.9819,53.6229),B(176.4487,69.8868) 将它与C=2时的C均值聚类结果进行比较,分别比较它们的结果图以及聚类中 分析:比较发现利用分级聚类方法与利用C均值聚类法时 C取2时的聚类结果极其相似 . 五、心得体会 通过本次试验,我们队C均值聚类法以及分级聚类法都有了较好的理解,并且在用MATLAB编程方面都有了很大进步。 部分代码: SPSS 聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练 SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T 检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用 K-Mean法把 31 省分成 3 类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从 Word文档复制到 Excel ,并进一步导入到 SPSS数据文件中。 分析:由于本实验中要对 31 个个案进行分类,数量比较大,用系统聚类法当然也 可以得出结果,但是相比之下在数据量较大时, K 均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类: 生成新变量总消费支出 =各变量之和如图所示: 2.对变量食品支出和居住支出进行配对样本 T 检验,如图所示: 得出结论: 3.对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。 初始聚类中心 聚类 123 食品支出7776.983052.575790.72衣着支出1794.061205.891281.25居住支出2166.221245.001606.27家庭设备及服务支出1800.19612.59972.24医疗保健支出1005.54774.89617.36交通和通信支出4076.461340.902196.88文化与娱乐服务支出3363.251229.681786.00其它商品和服务支出1217.70331.14499.30总消费支出23200.409792.6614750.02 迭代历史记录a 聚类中心内的更改 迭代123 11250.5921698.8651216.114 2416.86470.786173.731 3138.955 2.94924.819 446.318.123 3.546 5849.114319.1791362.411 6805.00415.199606.915 7161.001.72475.864 832.200.0349.483 9 6.440.002 1.185 10 1.2887.815E-5.148 心理学实验报告实验名称:系列位置效应实验 学院: 姓名: 学号: 摘要:本实验以汉字为材料,通过看汉字在系列中所处的位置、回忆延迟的时间和汉字呈现时间对自由联想的影响,称为系列位置效应。立即回忆对渐近部分没有影响,由于首因效应和近因效应正确回忆个数高,延迟回忆对渐近部分没有影响,首因效应正确回忆个数高,近因效应影响下降正确回忆个数降低。汉字材料呈现时长对首因效应回忆没有显著相关。 关键词:系列位置效应首应效应近因效应 一、导言 系列位置效应是指记忆材料在系列位置中所处的位置对记忆效果发生的影响,包括首因效应和近因效应。在系列学习(Serial Learning)中,在一系列处于不同位置的记忆材料回忆效果不同;系列位置效应就是这种接近开头和末尾的记忆材料的记忆效果好于中间部分的记忆效果的趋势。其开头和结尾记忆效果较好,分别叫首位效应(primacy effect)和近因效应(recency effect),而其效果较差的中间部分称为渐近部分。系列位置效应一般在自由回忆中出现,是双重记忆理论的重要证据。 本实验目标是验证系列位置效应,预期是立即回忆处于材料开始和末尾位置的汉字回忆正确比较多,汉字材料呈现时间长则首因效应明显,延迟回忆则会消除近因效应。 二、方法 2.1被试 被试为应用心理大三的学生共25人,9男16女,年龄为20~23岁,智力正常,视力及矫正视力正常,之前没有做过这个实验。 2.2仪器和材料 装载有实验程序的计算机 2.3实验设计 本实验使用了混合设计。自变量有三个分别是,汉字呈现的时间分为1s和2s;回忆的时间分为立即回忆和延迟回忆;汉字材料呈现的位置不相同。因变量为被试对呈现汉字的自由回忆正确率。 被试分为4组:1s立即回忆;1s延迟回忆;2s立即回忆;2s延迟回忆 3.4实验程序 实验开始将呈现20个汉字,需要被试尽量记住,当汉字呈现完成以后,被试需要在系 《数据分析》实验报告 班级: 07信计0班 学号: 姓名: 实验日期 2010-3-11 实验地点: 实 验楼505 实验名称: 样本数据的特征分析 使用软件名称:MATLAB 1. 熟练掌握利用Matlab 软件计算均值、方差、协方差、相关系数、标准差 与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2. 熟练掌握jbtest 与lillietest 关于一元数据的正态性检验; 3. 掌握统计作图方法; 4. 掌握多元数据的数字特征与相关矩阵的处理方法; 安徽省1990-2004年万元工业GDP 废气排放量、废水排放量、固体废物排放 量以及用于污染治理的投入经费比重见表 6.1.1,解决以下问题: 表6.1.1 实 验 目 的 1. 计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2. 计算各指标的偏度、峰度、三均值以及极差; 3?做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDR废气排放量,安徽省与江苏省是否 服从同样的分布? 程序如下: clear;clc format ba nk %保留两位小数 %%%%%%%%%%%安徽省%数据%%%%%%%%%%%%%%%%%% A=[104254.40 519.48 441.65 0.18 94415.00 476.97 398.19 0.26 89317.41 119.45 332.14 0.23 63012.42 67.93 203.91 0.20 45435.04 7.86 128.20 0.17 46383.42 12.45 113.39 0.22 39874.19 13.24 87.12 0.15 38412.85 37.97 76.98 0.21 35270.79 45.36 59.68 0.11 35200.76 34.93 60.82 0.15 35848.97 1.82 57.35 0.19 40348.43 1.17 53.06 0.11 40392.96 0.16 50.96 0.12 37237.13 0.05 43.94 0.15 34176.27 0.06 36.90 0.13]; %计算各指标的均值、方差、标准差、变异系数、偏度、峰度以及极差 A1=[mea n(A);var(A);std(A);std(A)./mea n(A);skew ness(A,0);kurtosis(A,0)-3;ra nge( A)] %E均值 A2=[1/4 1/2 1/4]*prctile(A,[25 50 75]) % 十算各指标的相关系数矩阵 A3=corrcoef(A) %做岀各指标数据直方图 subplot(221),histfit(A(:,1),8) subplot(222),histfit(A(:,2),8) subplot(223),histfit(A(:,3),8) subplot(224),histfit(A(:,4),7) %检验该数据是否服从正态分布 for i=1:4 [h(i),p(i),lstat(i),cv(i)]=lillietest(A(:,i),0.05); end h,p %十算岀前二列不服从正态分布,利用boxcox变换以后给岀该数据的密度函数[t1,l1]=boxcox(A(:,1)) [t2,l2]=boxcox(A(:,2)) [t3,I3]=boxcox(A(:,3)) 数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58- 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据: 对数据进行聚类分析实验报告 1.方法背景 聚类分析又称群分析,是多元统计分析中研究样本或指标的一种主要的分类方法,在古老的分类学中,人们主要靠经验和专业知识,很少利用数学方法。随着生产技术和科学的发展,分类越来越细,以致有时仅凭经验和专业知识还不能进行确切分类,于是数学这个有用的工具逐渐被引进到分类学中,形成了数值分类学。近些年来,数理统计的多元分析方法有了迅速的发展,多元分析的技术自然被引用到分类学中,于是从数值分类学中逐渐的分离出聚类分析这个新的分支。结合了更为强大的数学工具的聚类分析方法已经越来越多应用到经济分析和社会工作分析中。在经济领域中,主要是根据影响国家、地区及至单个企业的经济效益、发展水平的各项指标进行聚类分析,然后很据分析结果进行综合评价,以便得出科学的结论。 2.基本要求 用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C均值和分级聚类方法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。 3.实验要求 (1)把FAMALE.TXT和MALE.TXT两个文件合并成一个,同时采用身高和体重数据作为特征,设类别数为2,利用C均值聚类方法对数据进行聚类,并将聚类结果表示在二维平面上。尝试不同初始值对此数据集是否会造成不同的结果。 (2)对1中的数据利用C均值聚类方法分别进行两类、三类、四类、五类聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出合理的类别数目。 (3)对1中的数据利用分级聚类方法进行聚类,分析聚类结果,体会分级聚类方法。。(4)利用test2.txt数据或者把test2.txt的数据与上述1中的数据合并在一起,重复上述实验,考察结果是否有变化,对观察到的现象进行分析,写出体会 4.实验步骤及流程图 根据以上实验要求,本次试验我们将分为两组:一、首先对FEMALE 与MALE中数据组成的样本按照上面要求用C均值法进行聚类分析,然后对FEMALE、MALE、test2中数据组成的样本集用C均值法进行聚类分析,比较二者结果。二、将上述两个样本用分即聚类方法进行聚类,观察聚类结果。并将两种聚类结果进行比较。 (1)、C均值算法思想 系列位置效应 摘要:该实验以汉字为材料,以自由回忆任务的实验,考察不同呈现速度和回忆方式下的系列位置效应,实验结果在系列位置曲线中显示了机能的双重分离,支持有关近因效应来自短时记忆而首音效应来自长时记忆的观点。 关键字:系列位置效应、近因效应、首音效应、渐近线 1.导言 由一系列项目组成的学习材料,在学习过程中,每个项目学习的快慢、记忆的巩固程度,都与这个项目在系列中的位置有关。即学习材料在系列中的位置对记忆效果有影响,这种影响就叫做系列位置作用。 Ebbinghaus最早研究了系列位置作用。他用一系列无意义音节作学习材料,发现开始的部分最容易学(首音效应),其次是最末后的部分(近因效应),中间偏后一点的项目最难学(渐近线)。许多许多心理学家进一步的实验中发现迷宫学习中也存在系列位置的作用。L.B.Ward用12个无意义音节做学习材料,得出了一个比较典型的系列位置曲线。 研究证明,影响系列位置作用的因素有:(1)学习的方式。集中学习比分散学习对系列中部的项目更难记些,系列位置作用更明显。(2)材料的长度。材料越长,首末项的错误反应次数越多。(3)材料呈现的时间。呈现时间延长,学习效率提高。(4)再现的方式。若使自由再现,系列位置曲线的尾部上升的较高。 大多数支持短时存储不同于长时存储的证据来自自由回忆任务(free recall task)的实验。这种实验呈现一系列项目(单词居多),呈现完毕要求被试回忆项目(可不按顺序)当把回忆结果以项目呈现顺序为横坐标,以争取回忆率为纵坐标作图,会得到系列位置曲线(serial position curve)。研究者指出,近因效应来自于短时记忆,首音效应来自于长时存储。为证明这一设想,则需在系列位置曲线中实现机能的双重分离(functional double dissociation):某些自变量影响首音效应和渐近线,但不影响近因效应;另一些变量影响近因效应,但不影响首音效应和渐近线。属于前者的自变量有单词频率、呈现速度、系列长度、以及心理状态;属于后者的主要是系列单词呈现完毕后的干扰活动。 本实验即是基于此设想的实验。由前人的实验推测本实验结果:汉字呈现速度将影响首音效应和渐近线,但不影响近因效应;系列汉字横先完毕后的干扰作用将影响近因作用但不 《数据分析》 实验报告册 20 15 - 20 16 学年第一学期 班级: 学号: 姓名: 授课教师:实验教师: 目录 实验一网上书店的数据库创建及其查询 实验1-1 “响当当”网上书店的数据库创建 实验1-2 “响当当”网上书店库存、图书和会员信息查询 实验1-3 “响当当”网上书店会员分布和图书销售查询 实验二企业销售数据的分类汇总分析 实验2-1 Northwind公司客户特征分析 实验2-2 “北风”贸易公司销售业绩观测板 实验三餐饮公司经营数据时间序列预测 实验3-1 “美食佳”公司半成品年销售量预测 实验3-2 “美食佳”公司月管理费预测 实验3-3 “美食佳”华东分公司销售额趋势预测 实验3-4 “美食佳”公司会员卡发行量趋势预测 实验3-5 “美食佳”火锅连锁店原料年度采购成本预测 实验四住房建筑许可证数量的回归分析 实验4-1 “家家有房”公司建筑许可证一元线性回归分析实验4-2 “家家有房”公司建筑许可证一元非线性回归分析实验4-3 “家家有房”公司建筑许可证多元线性回归分析实验4-4 “家家有房”公司建筑许可证多元非线性回归分析 实验五手机用户消费习惯聚类分析 实验六新产品价格敏感度测试模型分析 实验一网上书店的数据库创建及其查询实验1-1 “响当当”网上书店的数据库创建 实验类型:验证性实验学时:2 实验目的: ?理解数据库的概念; ?理解关系(二维表)的概念以及关系数据库中数据的组织方式; ?了解数据库创建方法。 实验步骤: 这个实验我们没有直接做,只是了解了一下数据库的概念。 实验1-2 “响当当”网上书店库存、图书和会员信息查询 实验目的 ?理解odbc的概念; ?掌握利用microsoft query进行数据查询的方法。 实验步骤: 1..建立odbc数据源:启动microsoft office query应用程序,在microsoft office query应用程序窗口中,执行“文件/新建”命令,出现“选择数据源”对话框,单击“确定”按钮,出现“创建新数据源”对话框,按照要求做相应的操作。 选择数据源对话框创建新数据源窗口 做图上所示的选择odbc microsoft access安装对话框 实验报告 姓名学号专业班级 课程名 统计分析SPSS软件实验室 称 成绩指导教师 实验名称SPSS的聚类分析 1、实验目的: 掌握层次聚类分析和K-Means聚类分析的基本思想和具体,并能够对分析结果进行解释。 二、实验题目: 1.、现要对一个班同学的语文水平进行聚类,拟聚为三类,聚类依据是 两次语文考试的成绩。数据如下表所示。试用系统聚类法和K-均值法进 行聚类分析。 人名第一次语文成绩第二次语文成绩 张三9998 王五8889 赵四7980 小杨8978 蓝天7578 小白6065 李之7987 马武7576 郭炎6056 刘小100100 3、实验步骤(最好有截图): 1.先打开常用软件里的SPSS 11.5 for Windows.exe,在Variable View 中根据题目输入相关数据,如下图所示 2.在Data View中先输入数据,结果如下图所示 3. 首先试用系统聚类法对相关数据进行聚类 4. 选择菜单:【Analyze】→【Classify】→【Hierarchical Cluster】,然后选择参与层次聚类分析的变量两次语文考试的成绩到【Variable(s)】框中,再选择一个字符型变量“人名”作为标记变量到【Label Cases by】框中。 5.按“Plots”后进行选择 6.按“Statistics”后进行选择 7.按“Method”后进行选择 8.对第一个表格进行保存,并且命名为“语文水平.sav”,同时保存输出结果 4、实验结果及分析(最好有截图): 第一题: 1. 首先试用系统聚类法对相关数据进行聚类 《两点阈测量》实验报告 夏松(2009105020417) 湖北师范学院教育科学学院0904班 1 引言 维耶罗特(vierordt,1870)最早使用两点阈量规对人体各个部分的两点阈进行了测量,结果发现从局部到指尖,两点阈越来越小,这种身体触觉感受性随运动能力的增高而增高的现象,被称为是维耶罗特定律。除此之外,还有研究发现:两点阈因练习而减小,因疲劳而增大。 1.1 实验逻辑 当两点同时刺激时,只有达到一定的距离(两点阈),被试才有可能分辨出来。而随着这两点距离的缩小,被试越来越觉得此两点而不是一点。实验记录在不同距离下的刺激被试回答两点或一点的次数,求得感觉两点的百分数。 1.2 实验假设 假设所呈现的刺激,即两点距离为自变量,被试的反应为因变量。确定自变量的范围,在自变量的范围内记录被试的反应(一点还是两点)。 1.3 实验预期 用两个刺激物同时刺激皮肤,当刺激间的的间距足够大时,我们可以清晰分辨此为相隔一定距离的两点,当间距逐渐缩小,我们越来越难以分辨此为两点,当间距逐渐缩小到一定程度时,我们只能感觉到一点。 2 方法 2.1 被试 被试2人(互为主试、被试) 2.2 实验材料 两点阈量规:由一个游标卡尺和A、B两个刺激点组成,量脚之间的距离可以调节,并在刻度上读出来。 此外还有遮眼罩和记录纸。 2.3 实验设计 采用被试内设计。自变量为呈现两个刺激之间的距离,因变量为被试的反应。在被试手背或手臂上划好区域B通过预测得出两点阈的范围,再确定五个水平。然后施测,每个水平随机施测八次,记录被试反应(+为两点-为一点) 2.4 实验程序 主试选定被试的B区,只测量手臂的两点阈 在使用两点阈量规时,必须垂直接触皮肤,对两个尖点施力均匀,接触时间不能超过2秒钟,现在自己手上练几次后,再在被试的非实验区练习几次。 实验序列的长度和起点,可以根据初步测验后确定,大致在11-19mm的范围 《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布? 聚类分析实验报告记录 ————————————————————————————————作者:————————————————————————————————日期: 《应用多元统计分析》 课程实验报告 实验名称:用聚类分析的方法研究山东省17个市的产业类型 的差异化 学生班级:统计0901 学生姓名:贾绪顺杜春霖陈维民张鹏 指导老师:____________张艳丽_____________________ 完成日期:2011.12.12 一,实验内容 根据聚类分析的原理,使用系统聚类分析的COMplete linkage (最长距离法)和WARD(离差平方和法),运用SPSS软件对2009年山东省17个城市生产总值的数据进行Q型聚类,将17个城市分为5类,发现不同城市产业类型的差异化,并解释造成这种差异的原因 二,实验目的 希望通过实验研究山东省17个市的生产总值的差异化,并分析造成这种差异化的原因,可以更深刻的掌握聚类分析的原理;进一步熟悉聚类分析问题的提出、解决问题的思路、方法和技能;达到能综合运用所学基本理论和专业知识;锻炼收集、整理、运用资料的能力的目的;希望能会调用SPSS软件聚类分析有关过程命令,并且可以对数据处理结果进行正确判断分析,作出综合评价。 三,实验方法背景与原理 3.1方法背景 聚类分析又称群分析,是多元统计分析中研究样本或指标的一种主要的分类方法,在古老的分类学中,人们主要靠经验和专业知识,很少利用数学方法。随着生产技术和科学的发展,分类越来越细,以致有时仅凭经验和专业知识还不能进行确切分类,于是数学这个有用的工具逐渐被引进到分类学中,形成了数值分类学。近些年来,数理统计的多元分析方法有了迅速的发展,多元分析的技术自然被引用到分类学中,于是从数值分类学中逐渐的分离出聚类分析这个新的分支。结合了更为强大的数学工具的聚类分析方法已经越来越多应用到经济分析和社会工作分析中。在经济领域中,主要是根据影响国家、地区及至单个企业的经济效益、发展水平的各项指标进行聚类分析,然后很据分析结果进行综合评价,以便得出科学的结论。 聚类分析源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。聚类分析的主要应用,在商业方面,最常见的就是客户群的细分问题,可以从客户人口特征、消费行为和喜好方面的数据,对客户进行特征分析,充分利用数据进行客户的客观分组,使诸多特征有相似性的客户能被分在同一组内,而不相似的客户能被区分到另一些组中。在生物方面,聚类分析可以用来对动植物进行分类,对基因进行分类等,从而获取对动植物种群固有结构的认识,对物种进行很好的分类。在电子商务方面,聚类分析在电子商务中网站建设数据挖掘中也是很重要的一个方面,通过对客户的浏览行为、浏览网站、客户的年龄等,对客户进行分析,找出不同客户的共同特征,通过共同特征对客户进行分类,可以帮助电子商户更好的了解他们的客户,并向客户提供更合适的服务。在保险行业上,根据产、寿险进行分类,不同类别的公司进行分类,对保险投资比例进行分类管理,从而提高保险投资的效率。 3.2实验的方法与原理 聚类分析是研究“物以类聚”的一种科学有效的方法。做聚类分析时,出于不同的目的和要求,可以选择不同的统计量和聚类方法。 聚类分析方法中最常用的一种是系统聚类法,其基本思想是:先将待聚类的n个样品(或者变量)各自看成一类,共有n类;然后按照选定的方法计算每两类之间的聚类统计量,即某种距离(或者相似系数),将关系最为密切的两类合为一类,其余不变,即得到n-1类;再按照前面的计算方法计算新类与其他类之间的距离(或相似系数),再将关系最为密切的 学生实验报告 注:1.指导教师和学生成绩一栏由指导教师填写,其它栏目内容均由学生填写。 2.“实验项目名称”要与该实验课程教学大纲中的“实验项目”相对应。 附一: 四、实验指南 (一)宏观经济分析的基本方法 1.总量分析法 总量分析法是对影响宏观经济的总量指标进行分析,如GDP,消费额、投资额、银行贷款总额、物价水平等。总量分析主要是一种动态分析,主要研究总量指标的变动规律 2.结构分析法 是指对经济系统中各组成部分及其对比关系变动规律的分析。比如分析第一产业、第二产业、第三产业之间的比例,分析消费与投资的比例关系。结构分析主要是一种静态分析,即对一定时间内经济系统中各组成部分变动规律的分析 3.宏观分析资料的搜集与处理 宏观分析所需的有效资料一般包括政府的重点经济政策与措施、一般生产统计资料、金融物价统计资料、贸易统计资料、每年国民收入统计与景气动向、突发性非经济因素等。 (二)宏观经济分析的主要内容 宏观经济分析主要包括宏观经运行的变动、宏观经济政策、国际金融环境以及对证券市场的 供求关系等几个方面。当然像人口因素、能源因素以及包括政治因素、战争因素、灾害因素都有可能对证券市场产生决定性的影响,但在一般情况下,上述因素的作用机制必须单独分析研究。宏观经济分析的内容重在对宏观经济形势与经济背景作出基本判断,以分析在新兴加转型背景下中国宏观经济对证券市场的的影响,把握证券市场总体变动趋势,掌握宏观经济政策对证券市场的影响力度与方向,判断整个证券市场的投资价值。 1.宏观经济变动对证券市场的影响 宏观经济分析最重要的参考依据要选取官方公开公布的数据,尤其是国家统计局的数据相对最可靠。可借助统计工具与手段,了解证券价格变化与经济运行形势的关联性。 宏观经济分析包含的内容有许多,在此可重点选取几个方面进行分析,比如可以以国民生产总值对证券价格的影响,看看经济持续增长与衰退对证券市场的影响;也可以选取就业状况的变动对证券市场影响分析,就业状况的好坏不仅反映了经济状况,而且对证券市场资金供给的增减变化有密切关系。通过具体因素的分析,掌握宏观经济形势对证券市场的影响方式与影响程度。宏观经济的运行形势对证券市场的影响可见表3-1、3-2、3-3。 表3-1 评价宏观经济形势的基本指标 表3-2 宏观经济运行对证券市场的影响 实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。 2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。 五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 聚类分析实验报告 姓名: 学号: 班级: 一:实验目的 1.了解聚类分析的基本原理及在spss中的实现过程。 2.通过对指标进行聚类,体会降维的处理过程。 3.通过不同性质指标对样本进行聚类,体会归类的思想。 二:实验原理 聚类分析就是根据事物本身的特性来定量研究分类问题的一种多元统计分析方法。其基本思想就是同一类中的个体有较大的相似性,不同类中的个体差异较大,于就是根据一批根据一批样品的多个观察指标,找出能够度量样品(或变量)之间相似度的统计量,并以此为依据,采用某种聚类法,将所有的样品(或变量)分别聚合到不同的类中。 三:实验过程 本实验就是通过对上市公司分析所得。由基本经济知识知道评价一个上市公司的业绩主要从以下四个方面:盈利能力,偿债能力,成长能力,经营能力。所以我分别从这四个方面共选取了19个指标来对上市公司的业绩进行评价。具体数据请见EXCEL。 由上面的分析我们知道评定一个上市公司业绩的指标有四类,但我们瞧EXCEL可知,每一类下面有4-5个指标,每类指标有较强相关性,存在多重共线性与维数过高而不易分析得影响。所以首先采用系统聚类法对每类指标进行聚类,再采用比较复相关系数得出每类最具代表的指标,达到降维的目的。(注:以下对指标分析均采用主间连接法,度量标准为person相关性) 以下就是实验截图: (1):对盈利能力指标 从上表分析我们可将盈利能力的4个指标分为两类,即“毛利率”为一类,“销售净利率”、“成本费用利润率”与“资产净利润”为一类。所以“毛利率”为一类,另外再对“销售净利润”、“成本费用利润率”与“资产净利润”分别作对另3个指标的复相关系数,结果如下: ①、以“销售净利润”为因变量,其余为自变量得: 模型汇总 模型R R 方调整 R 方标准估计的误 差 1 、980a、960 、957 、20721755 a、预测变量: (常量), Zscore: 资产净利率(%), Zscore: 毛利率(%), Zscore: 成本费用利润率(%)。 ②、以“成本费用利润率”为因变量,其余为自变量得: 模型汇总 模型R R 方调整 R 方标准估计的误 差 1 、978a、957 、953 、21603919 a、预测变量: (常量), Zscore: 销售净利率(%), Zscore: 毛利率(%), Zscore: 资产净利率(%)。 ③、以“资产净利润”为因变量,其余为自变量得: 模型汇总 模型R R 方调整 R 方标准估计的误 差 对数据进行聚类分析实验报告 徐远东 任争刚 权荣 一、 基本要求 用FAMALE.TXT 、MALE.TXT 和/或test2.txt 的数据作为本次实验使用的样本集,利用C 均值和分级聚类方法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。 二、 实验要求 1、 把FAMALE.TXT 和MALE.TXT 两个文件合并成一个,同时采用身高 和体重数据作为特征,设类别数为2,利用C 均值聚类方法对数据进行聚类,并将聚类结果表示在二维平面上。尝试不同初始值对此数据集是否会造成不同的结果。 2、 对1中的数据利用C 均值聚类方法分别进行两类、三类、四类、五类聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出合理的类别数目。 3、 对1中的数据利用分级聚类方法进行聚类,分析聚类结果,体会分级聚类方法。。 4、 利用test2.txt 数据或者把test2.txt 的数据与上述1中的数据合并在一起,重复上述实验,考察结果是否有变化,对观察到的现象进行分析,写出体会 三、 实验步骤及流程图 根据以上实验要求,本次试验我们将分为两组:一、首先对FEMALE 与MALE 中数据组成的样本按照上面要求用C 均值法进行聚类分析,然后对FEMALE 、MALE 、test2中数据组成的样本集用C 均值法进行聚类分析,比较二者结果。二、将上述两个样本用分即聚类方法进行聚类,观察聚类结果。并将两种聚类结果进行比较。 一、(1)、C 均值算法思想 C 均值算法首先取定C 个类别和选取C 个初始聚类中心,按最小距离原则将各模式分配到C 类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各模式到其判属类别中心的距离平方之和最小 (2)、实验步骤 第一步:确定类别数C ,并选择C 个初始聚类中心。本次试验,我们分别将C 的值取为2和3。用的是凭经验选择代表点的方法。比如:在样本数为N 时,分为两类时,取第一个点和第()12/+N INT 个点作为代表点;分为三类时,取第一、 实验心理学实验 实验名称:群体实验演示:画线的准确性 一、 问题(1分) “知道结果”(反馈)的信息对画线准确性有何影响 二、 假设(1分) H 0:如果“知道结果”(反馈)的信息对画线的准确性无影响,那么有反馈和无反馈两种情况下画线的成绩无明显差异。 H 1:如果“知道结果”(反馈)的信息对画线的准确性有影响,那么有反馈和无反馈两种情况下画线的成绩有明显差异。 三、 预期(1分) “知道结果”(反馈)的信息,有反馈和无反馈两种情况下画线的成绩有明显差异。 四、 方法(4分) 2、 仪器设备(0.5分) 铅笔、直尺、橡皮、白纸 3、 变量(1分) 3.1自变量:有无反馈 3.2因变量:画线的准确性 3.3控制变量:纸张、直尺完全相同 4、 实验设计(1分) 单因素组间设计 5、 实验任务和流程(1分) a. 让全班同学分成两组,两两组合,对坐在桌旁。桌上放好画有黑色线段的白纸, 每人一张,两张完全相同。 b. 让B 组同学用纸或挡板遮住A 组作者的视线,使他看不到自己的画线的手和 画出的线。 c. B 组同学念指示语:“请你用平时写字的手那好铅笔。眼睛看着这张白纸上的 班级:15应用心理学1班 姓名:刘明明 学号:2015326670025 实验日期:9.23 指导老师:胡信奎 的黑色竖线,用笔在旁边的白纸上画一根相同长度的竖线。请你按照你看到的 长度来画,一直画到和看到的线一样长。画的时候,你不能看自己的画线的手 和画好的线。一共20次。从左到右。我会帮助你移动白纸,你手臂不要移动, 尽量画准确。” d.被试明白后开始实验。A组同学完成20 条竖线后结束。 e.两组对换。A组同学年指导语:“现在请你用相同的方法画线。这次你每完成 一条线,我会告诉你结果。但是,我只告诉你画的线是长了、短了还是刚好。 (误差<5%为刚好)。请你注意自己画线的感觉,并记住这种感觉。如果我告 诉你这次画长了,那么下次就画短一点。一共画10次,我会帮助你移动白纸, 你手臂不要移动,尽量画准确。” f.每当B组被试画好一条线,主试尽快良好,立刻告诉被试结果。移动白纸, 直到20条线画完。 g.A组重复无反馈的实验。 h.B组重复有反馈的实验 6、统计方法(可以体现在结果分析里) 用平均数、标准差和方差分析来进行统计分析 五、结果 1、单个被试的数据分析(数据+统计+分析:1.5分) 表1 单组被试画线长度与标准长度的误差(单位,n=40) 自变量 A(李夏涵)B(刘明明) 因变量 2.47±0.77 0.87±0.46 (mean±sd) *配对t检验,无反馈(A)vs有反馈(B) 由表1可见,在无反馈的情况下,被试误差的平均数相对与有反馈组的误差平均数更大,说明在无反馈的情况下,所画线与标准普遍相差较大;同样的,A组被试标准差相对与B组的标准差更大,说明在无反馈组所画线的长度更加不确定。 2、全组数据的比较分析(数据+统计+分析:1.5分) 表2 全组被试画线长度与标准长度的误差(cm,mean±sd) 自变量 A(无反馈)B(有反馈) 因变量 2.11±1.23 0.87±0.39 (mean±sd) SSt=∑∑(Xij—Xt)^2=92.38 SSb=n*∑(Xj—Xt)^2=26.52 SSw=∑∑(Xij—Xj)^2=66.86 dft=nk-1=33 dfb=k-1=1 dfw=n(k-1)=32 MSb=SSb/dfb=26.52 实验一SAS系统的使用 【实验类型】(验证性) 【实验学时】2学时 【实验目的】使学生了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。 【实验内容】 1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗口、日志窗口、输出窗口之间切换。 2. 建立数据集 表1 Name Sex Math Chinese English Alice f908591 Tom m958784 Jenny f939083 Mike m808580 Fred m848589 Kate f978382 Alex m929091 Cook m757876 Bennie f827984 Hellen f857484 Wincelet f908287 Butt m778179 Geoge m868582 Tod m898484 Chris f898487 Janet f866587 1)通过编辑程序将表1读入数据集sasuser.score; 2)将下面记事本中的数据读入SAS数据集,变量名为code name scale share price: 000096 广聚能源8500 0.059 1000 13.27 000099 中信海直6000 0.028 2000 14.2 000150 ST麦科特12600 -0.003 1500 7.12 000151 中成股份10500 0.026 1300 10.08 000153 新力药业2500 0.056 2000 22.75 3)将下面Excel表格中的数据导入SAS数据集work.gnp; name x1 x2 x3 x4 x5 x6 北京190.33 43.77 7.93 60.54 49.01 90.4 天津135.2 36.4 10.47 44.16 36.49 3.94 河北95.21 22.83 9.3 22.44 22.81 2.8 山西104.78 25.11 6.46 9.89 18.17 3.25 内蒙古128.41 27.63 8.94 12.58 23.99 3.27 辽宁145.68 32.83 17.79 27.29 39.09 3.47 吉林159.37 33.38 18.37 11.81 25.29 5.22 黑龙江116.22 29.57 13.24 13.76 21.75 6.04 上海221.11 38.64 12.53 115.65 50.82 5.89 江苏144.98 29.12 11.67 42.6 27.3 5.74 浙江169.92 32.75 21.72 47.12 34.35 5 安徽153.11 23.09 15.62 23.54 18.18 6.39 福建144.92 21.26 16.96 19.52 21.75 6.73 江西140.54 21.59 17.64 19.19 15.97 4.94 山东115.84 30.76 12.2 33.1 33.77 3.85 河南101.18 23.26 8.46 20.2 20.5 4.3 湖北140.64 28.26 12.35 18.53 20.95 6.23 湖南164.02 24.74 13.63 22.2 18.06 6.04 广东182.55 20.52 18.32 42.4 36.97 11.68 广西139.08 18.47 14.68 13.41 20.66 3.85 四川137.8 20.74 11.07 17.74 16.49 4.39 贵州121.67 21.53 12.58 14.49 12.18 4.57 云南124.27 19.81 8.89 14.22 15.53 3.03 陕西106.02 20.56 10.94 10.11 18 3.29 甘肃95.65 16.82 5.7 6.03 12.36 4.49 青海107.12 16.45 8.98 5.4 8.78 5.93 宁夏113.74 24.11 6.46 9.61 22.92 2.53完整word版,SPSS聚类分析实验报告.docx
实验心理学实验报告6
数据分析实验报告
数据分析实验报告
对数据进行聚类分析实验报告
心理学实验报告模板
数据分析实验报告册
SPSS的聚类分析实验报告
实验心理学 实验报告1
数据分析实验报告
聚类分析实验报告记录
宏观经济实验报告
数据挖掘实验报告三
数据分析实验报告
聚类分析实验报告
对数据进行聚类分析实验报告
《实验心理学实验》实验报告 刘明明
数据分析实验报告