2×2析因设计资料的方差分析

2×2析因设计资料的方差分析
用A药和B药治疗高胆固醇患者,并考虑是否患糖尿病对结果的影响,故把高胆固醇患者分成糖尿病且高胆固醇组和单纯高胆固醇组,每一种病情组又随机分为两组:一组用A药,一组用B药,经过一个疗程后,观察患者的总胆固醇下降的幅度,具体数据列表如下,对该资料做统计分析。
不同病情不同疗法治疗高胆固醇患者的总胆固醇下降值(mmol/L)
本例中,以总胆固醇下降幅度为疗效指标,以高血脂患者为研究对象,主要的研究问题是评价A药和B药降低总胆固醇的幅度,由于该研究考虑了研究对象是否患有糖尿病的因素,所以要回答两个药的疗效差别如何。根据最终结果,研究者有时可以直接称A药疗效优于B药,或者B药疗效优于A药,或者两个药疗效相同;但研究者往往不能这样简单地评价两个药的疗效,因为最终结果往往有多种可能的答案,可以归纳为下列三大类的情况。
1)A药和B药的疗效相同或不同,但两个药的疗效差异与是否患糖尿病无关。
2)无糖尿病的患者而言,两个药的疗效相同,对于糖尿病患者而言,两种药物的疗效不同。
3)对于糖尿病患者而言,两种药物的疗效相同,无糖尿病的患者而言,两个药的疗效不同。
如果资料符合方差分析的条件,可以用两因素方差分析进行统计分析,方差分析中的交互作用概念正是反映了上述第2种和第3种答案,即:交互作用是指某个因素对效应指标的作用与另一个因素处于何种水平状态有关(本例中治疗方案因素对疗效的作用与患者是否患糖尿病有关)。因此如果本例中治疗方案因素对疗效的作用与患者是否患糖尿病无关,则称治疗方案与是否患糖尿病对效应指标(降低总胆固醇)没有交互作用。
先考虑无交互作用的方差分析模型如下:
糖尿病的高血脂患者用B药治疗一个疗程后,总胆固醇平均下降μ(mmol/L),
糖尿病的高血脂患者用A药治疗一个疗程后,总胆固醇平均下降μ+β1(mmol/L),即糖尿病的高血脂患者用A药和用B药治疗一个疗程,两种药的疗效:总胆固醇下降幅度的平均差异为β1(mmol/L);
无糖尿病的高血脂患者用B药治疗一个疗程后,总胆固醇平均下降μ+β2(mmol/L),即同样用B药,有糖尿病的高血脂患者和无糖尿病的高血脂患者的总胆固醇下降幅度平均相差β2(mmol/L);
无糖尿病的高血脂患者用A药治疗一个疗程后,总胆固醇平均下降μ+β1+β2(mmol/L),即同样用A药,有糖尿病的高血脂患者和无糖尿病的高血脂患者的总胆固醇下降幅度平均相差β2(mmol/L)。
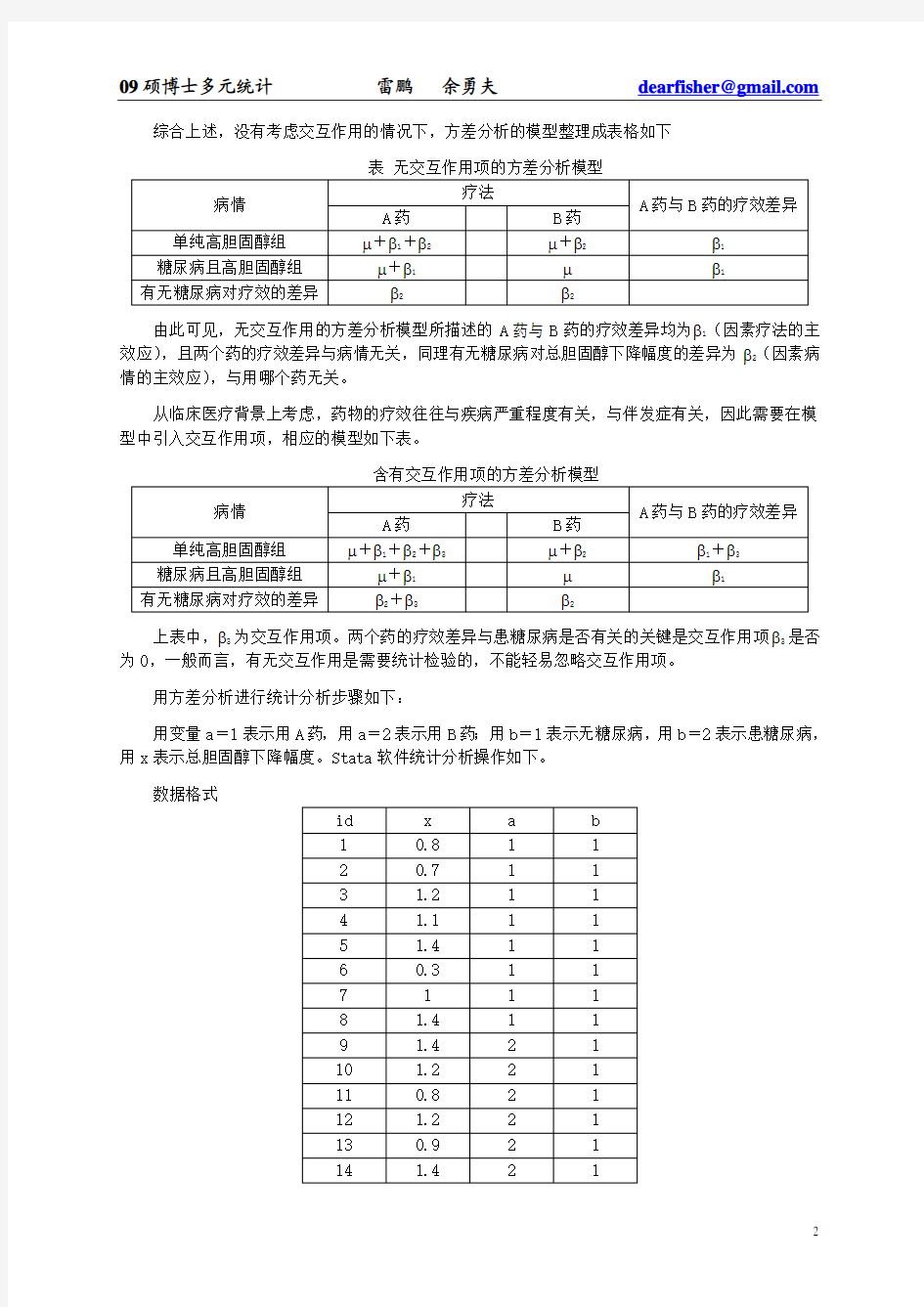
综合上述,没有考虑交互作用的情况下,方差分析的模型整理成表格如下
表无交互作用项的方差分析模型
由此可见,无交互作用的方差分析模型所描述的A药与B药的疗效差异均为β1(因素疗法的主效应),且两个药的疗效差异与病情无关,同理有无糖尿病对总胆固醇下降幅度的差异为β2(因素病情的主效应),与用哪个药无关。
从临床医疗背景上考虑,药物的疗效往往与疾病严重程度有关,与伴发症有关,因此需要在模型中引入交互作用项,相应的模型如下表。
含有交互作用项的方差分析模型
上表中,β3为交互作用项。两个药的疗效差异与患糖尿病是否有关的关键是交互作用项β3是否为0,一般而言,有无交互作用是需要统计检验的,不能轻易忽略交互作用项。
用方差分析进行统计分析步骤如下:
用变量a=1表示用A药,用a=2表示用B药;用b=1表示无糖尿病,用b=2表示患糖尿病,用x表示总胆固醇下降幅度。Stata软件统计分析操作如下。
数据格式
由于方差分析要求资料的方差齐性,残差(residual)服从正态分布,故首先检验资料是否符合方差分析的条件。
正态性检验
H0:资料服从正态分布
H1:资料呈非正态分布
α=0.05
anova x a b a*b 先作方差分析
predict e, residual 计算残差,用变量e表示
swilk e 检验残差的正态性
残差正态性检验的结果如下
Shapiro-Wilk W test for normal data
Variable | Obs W V z Prob>z
-------------+-------------------------------------------------
e | 32 0.96810 1.064 0.129 0.44878
正态性检验的P值为0.44875>>0.05,故没有充分证据可以否认资料呈正态分布。
采用Levene’s方差齐性检验的方法检验方差齐性,操作如下:
H0:各组资料的方差齐性
H1:各组资料的方差不齐
α=0.10
gen ee=abs(e) 计算残差的绝对值,并存入变量ee
anova ee a b a*b 用方差分析的方法比较各组残差绝对值的平均值
主要结果如下
Number of obs = 32 R-squared = 0.1193
Root MSE = .153848 Adj R-squared = 0.0249
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | .089746089 3 .029915363 1.26 0.3058
a | .03611328 1 .03611328 1.53 0.2270
b | .023925778 1 .023925778 1.01 0.3233
a*b | .029707031 1 .029707031 1.26 0.2721
Residual | .662734328 28 .023669083
对应Model的F值为1.26,P值=0.3058>0.10,故不能认为方差不齐。
由于该研究考虑了是否患糖尿病因素对两个药的疗效比较的影响,因此统计分析时应首先检验是否存在交互作用。
H10:两种药的疗效差异与是否患糖尿病无关(β3=0)
H11:两种药的疗效差异与是否患糖尿病有关(β3≠0)
α=0.05
anova x a b a*b 方差分析
regress 估计模型中的μ,β1,β2和β3
主要的相关结果如下
------------------------------------------------------------------------------ x Coef. Std. Err. t P>|t| [95% Conf. Interval] ------------------------------------------------------------------------------ _cons .325 .0950211 3.42 0.002 .130358 .519642 a
1 .425 .134380
2 3.16 0.004 .1497347 .7002653
2 (dropped)
b
1 .8125 .134380
2 6.05 0.000 .5372347 1.087765
2 (dropped)
a*b
1 1 -.575 .1900423 -3.03 0.005 -.964284 -.185716 1
2 (dropped) 2 1 (dropped) 2 2 (dropped)
------------------------------------------------------------------------------
输出结果中的drop 表示没有这项参数或认为这项系数为0。输出结果显示?0.325μ
=,1?0.425β=,2?0.8125β=, 3
?0.575β=?,由于β3的P 值为0.005<0.05,即表明存在交互作用,可以认为两个药的疗效差异与是否患糖尿病有关。因此需要按是否患糖尿病分别进行两个药的疗效比
较。
H 0:两种药的疗效相同 H 1:两种药的疗效不同
由于需要比较两次,根据bonferroni 两两比较的方法,设置两两比较的校正α=0.05/2=0.025
对于糖尿病且高胆固醇患者(b =2)
用B 药治疗后(a=2)的总胆固醇平均下降幅度为?0.325μ
=(mmol/L) 用A 药治疗后(a=1)的总胆固醇平均下降幅度为1
??0.3250.4250.75μβ+=+=
(mmol/L),比用B 药
的平均下降幅度大0.425(mmol/L),β1的P 值=0.004<0.025,因此可以认为:对于患糖尿病的高血
脂患者,用A 药降低总胆固醇的疗效优于用B 药,差异有统计学意义。 对于未患糖尿病的高胆固醇患者(b =1)
用B 药治疗后(a=2)的总胆固醇平均下降幅度为2
??0.3250.8125 1.1375μβ+=+=
(mmol/L)
用A 药治疗后(a=1)的总胆固醇平均下降幅度为1??μβ++2?β+3?β=0.325+0.425+0.8125-0.575=0.9875(mmol/L),比用B 药的平均下降幅度大1
?β3?β+=0.425-0.575=0.15(mmol/L),因此需要检验β1+β3是否为0,用Stata 比较命令如下
test _b[a[1]]+_b[a[1]*b[1]]=0 检验H 0:β1+β3=0,H 1:β1+β3≠0 结果如下
( 1) a[1] + a[1]*b[1] = 0 F( 1, 28) = 3.09 Prob > F = 0.0898
检验H 0:β1+β3=0的P 值=0.0898>0.025,即:对于未患糖尿病的高血脂患者,用A 药与用B 药降
低总胆固醇的疗效差异无统计学意义,认为没有充分证据可推断两个药的疗效有差异。
小结
1、析因设计的资料用方差分析要求残差服从正态分布,方差齐性。如果资料不满足方差分析的条件,可以先进行秩变换或其它的正态性变换(如Box-cox变换,对数变换,反正弦变换等),然后再做统计分析。
2、析因设计的主要优点是:①同时评价多个因素各个水平的效应,所以析因设计是一种比较完备的设计,其结果比较容易解释。②能够分析各因素间的交互作用;③容许一个因素在其他各因素的几个水平上来估计其效应,所得结论在实验条件的范围内是有效的。
3、析因设计的主要缺点是:在研究因素较多的情况下,需要非常大的样本量,所以析因设计不能分析太多的研究因素。
4、析因设计的统计分析应首先评价是否存在交互作用。如果存在交互作用,则孤立地评价主效应是没有意义的,应根据具体的研究问题,进行简单效应比较(如例题统计分析步骤)。
5、析因设计的资料有时候误被当作完全随机设计的资料进行处理,如课本上的例题,就经常被看成单因素4水平设计,有一个“组别”因素,而这个因素分成第一组(用A药)、第二组(用B 药)、第三组(A、B两药均用)、第四组(A、B两药均不用)4个水平。若用完全随机设计的方差分析进行统计分析,则无法评价交互作用,特别若无交互作用时,每个因素各个水平之间的比较存在降低检验效能的问题。
6、析因设计一般要求各个因素的每种水平组合的重复数是相同的,并称为平衡设计模型,统计检验效能比较高。在特殊情况下,各个因素的每种水平组合的重复数出现不相同,则称为非平衡设计模型,在同样总样本量的情况下,统计检验效能相对较低。
方差分析和试验设计
6方差分析与试验设计 在研究一个或多个分类型自变量与一个数值型因变量之间的关系时,方差分析就是其中主要方法之一。检验多个总体均值是否相等的统计方法。 所要检验的对象称为因素。因素的不同表现称为水平。每个因子水平下得到的样本数据称为观测值。 随机误差:在同一行业(同一总体)下,样本的各观测值是不同的。抽样随机性造成。 系统误差:在不同一行业(不同一总体)下,样本的各观测值也是不同的。抽样随机性和行业本身造成的。 组内误差:衡量因素在同一行业(同一总体)下样本数据的误差。只包含随机误差。 组间误差:衡量因素在不同一行业(不同一总体)下样本数据的误差。包含随机误差、系统误差。 方差分析的三大假设: 每个总体服从正态分布; 每个总体的方差必须相同; 观测值是独立的; 单因素方差分析(F分布) 数据结构:表示第i个水平(总体)的第j个的观测值。(i列j行)分析步骤: 1提出假设。自变量对因变量没有显著影响 不完全相等自变量对因变量有显著影响 2构造检验的统计量 计算因素各水平的均值(各水平样本均值) 计算全部观测值的总均值(总体均值) 计算误差平方和: 总误差平方和SST:全部观测值与总平均值得误差平方和。 水平项误差平方和SSA:各组平均值与总平均值得误差平方和。组间平方和。 误差项平方和SSE:各样本数据与其组平均值误差的平方和。组内平方和。 SST=SSA+SSE
A B C D E F G 1 误差来源 平方和自由度均方F 值P 值 F 临界值2SS df MS 3组间(因素 来源)SSA k-1MSA MSA/MSE 4组内(误差)SSE n-k MSE 5 总和 SST n-1 计算统计量 各平方和除以它们对应的自由度,这一结果称为均方。 SST 的自由度为(n-1),其中n 为全部观测值的个数。 SSA 的自由度为(k-1),其中k 为因素水平的个数。(组数-1) SSE 的自由度为(n-k )。 SSA 的均方(组间均方)为 SSE 的均方(组内均方)为 3统计决策 在给定的显著性水平α下,查表得临界值 若,有显著影响; 若,无显著影响; 4方差分析表
第四节析因设计与方差分析
第四节析因设计与方差分析 1. 基本概念 完全随机设计(单因素) 随机区组设计(两因素, 无重复) 拉丁方设计(三因素, 无重复) 析因设计(两因素以上, 至少重复2次以上) 析因设计的意义 在评价药物疗效时,除需知道A药和B药各剂量的疗效外(主效应),还需知道两种药同时使用的协同疗效。析因设计及相应的方差分析能分析药物的单独效应、主效应和交互效应。 例:
A因素食物中蛋白含量; B因素食物中脂肪含量 B A 平均a2-a1 a1 a2 b1 30 32 31 2 b2 36 44 40 8 平均33 38 35.5 5 b2-b1 6 12 9
(1)单独效应: 在每个B 水平, A 的效应。或在每个A 水平,B 的效应。 (2)主效应:某因素各水平的平均差别。 (3)交互效应:某因素各水平的单独效应随另一因素水平变化而变化,则称两因素间存在交互效应。如果)()()(000μμμμμμ-+-≠-b a ab ,存在交互效应。 如果)()()(000μμμμμμ-+->-b a ab ,协同作用。 如果)()()(000μμμμμμ-+-<-b a ab ,拮抗作用。
25 27 29 31 33 35 37 39 41 43 45 a1a2 25 27 29 31 33353739414345 a1a2 如果不存在交互效应,则只需考虑各因素的主效应。 在方差分析中,如果存在交互效应,解释结果时,要逐一分析各因素的单独效应,找出最优搭配。 在两因素析因设计时,只需考虑一阶交互效应。三因素以上时,除一阶交互效应外,还需考虑二阶、三阶等高阶交互效应,解释将更复杂。
析因设计
常用实验设计方法(三) 六.析因设计(f a c t o r i a l d e s i g n) ◆析因设计是一种多因素试验设计。 ◆可将两个或多个因素的各个水平进行排列组合,交叉分组进行全面实验。 ◆总的实验方案(组合)是各因素水平的乘积。 例如: 2×2析因设计(两个因素,每个因素均为2个水平,常可写成22析因设计) A因素(A1、A2)和B因素(B1、B2)共4种实验方案或组合(A1B1、A1B2、A2B1、A2B2) 3×3析因设计(两个因素,每个因素均为3个水平,常可写成23析因设计) A因素(A1、A2、A3)和B因素(B1、B2、B3)共9种组合 (A1B1、A1B2、A1B3、A2B1、A2B2A2B3、A3B1、A3B2A3B3)2×3×3析因设计(三个因素,一个因素为2个水平,余均为3个水平)共18种组合 1.特点 ①研究的因素个数m≥2,各因素的水平数≥2; ②各因素在实验中同时实施且所处的地位基本平等。 ③每个因素水平相互组合的实验方案,至少进行2次及以上独立重复实验。 ④因素间存在交互效应。例如,一级(两个因素间)或二级交互(三个因素间)效应。 ⑤统计学分析时,各因素及交互项所用误差项是相同的。 ◆优点: ?可分析各因素的主效应(m a i n e f f e c t s)(某因素各水平间的平均效应差异) ?因素间的交互效应(i n t e r a c t i o n)(一个因素的水平改变会影响另一个因素的效应) ?寻找最优方案或最佳组合 ?可允许数据缺失(完全随机分配情况下) ◆缺点: ?当因素较多或水平数较多时,所需实验次数过多。 ?一般来说,因素数最好不要多于6个,水平数亦不要过多,一般为2或3个。
方差分析与试验设计
第10章 方差分析与试验设计 三、选择题 1. C 2. B 3. A 4. B 5. C 1.方差分析的主要目的是判断 ( )。 A. 各总体是否存在方差 B. 各样本数据之间是否有显著差异 C. 分类型自变量对数值型因变量的影响是否显著 D. 分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是 ( )。 A. 组间平方和除以组内平方和 B. 组间均方除以组内均方 C. 组间平方除以总平方和 D. 组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为 ( )。 A. 随机误差 B. 非随机误差 C. 系统误差 D. 非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为 ( )。 A. 组内误差 B. 组间误差 C. 组内平方 D. 组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 6. A 7. D 8. D 9. A 10.A 6.组内误差是衡量某一水平下样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定 ( )。 A. 每个总体都服从正态分布 B. 各总体的方差相等 C. 观测值是独立的 D. 各总体的方差等于0 8.在方差分析中,所提出的原假设是210:μμ=H = ···=k μ,备择假设是( ) A. ≠≠H 211:μμ···k μ≠ B. >>H 211:μμ···k μ> C. < 第三节正交试验设计及其方差分析 在工农业生产和科学实验中,为改革旧工艺,寻求最优生产条件等,经常要做许多试验,而影响这些试验结果的因素很多,我们把含有两个以上因素的试验称为多因素试验.前两节讨论的单因素试验和双因素试验均属于全面试验(即每一个因素的各种水平的相互搭配都要进行试验),多因素试验由于要考虑的因素较多,当每个因素的水平数较大时,若进行全面试验,则试验次数将会更大.因此,对于多因素试验,存在一个如何安排好试验的问题.正交试验设计是研究和处理多因素试验的一种科学方法,它利用一套现存规格化的表——正交表,来安排试验,通过少量的试验,获得满意的试验结果. 1.正交试验设计的基本方法 正交试验设计包含两个内容:(1)怎样安排试验方案;(2)如何分析试验结果.先介绍正交表. 正交表是预先编制好的一种表格.比如表9-17即为正交表L4(23),其中字母L表示正交,它的3个数字有3种不同的含义: (1) L4(23)表的结构:有4行、3列,表中出现2个反映水平的数码1,2. 列数 ↓ L4 (23) ↑↑ 行数水平数 (2)L4(23)表的用法:做4次试验,最多可安排2水平的因素3个. 最多能安排的因素数 ↓ L4(23) ↑↑ 试验次数水平数 (3) L4(23)表的效率:3个2水平的因素.它的全面试验数为23=8次,使用正交表只需从8次试验中选出4次来做试验,效率是高的. L4(23) ↑↑ 实际试验数理论上的试验数 正交表的特点: (1)表中任一列,不同数字出现的次数相同.如正交表L4(23)中,数字1,2在每列中均出现2次. (2)表中任两列,其横向形成的有序数对出现的次数相同.如表L4(23)中任意两列, 2×2析因设计资料的方差分析 用A药和B药治疗高胆固醇患者,并考虑是否患糖尿病对结果的影响,故把高胆固醇患者分成糖尿病且高胆固醇组和单纯高胆固醇组,每一种病情组又随机分为两组:一组用A药,一组用B药,经过一个疗程后,观察患者的总胆固醇下降的幅度,具体数据列表如下,对该资料做统计分析。 不同病情不同疗法治疗高胆固醇患者的总胆固醇下降值(mmol/L) 本例中,以总胆固醇下降幅度为疗效指标,以高血脂患者为研究对象,主要的研究问题是评价A药和B药降低总胆固醇的幅度,由于该研究考虑了研究对象是否患有糖尿病的因素,所以要回答两个药的疗效差别如何。根据最终结果,研究者有时可以直接称A药疗效优于B药,或者B药疗效优于A药,或者两个药疗效相同;但研究者往往不能这样简单地评价两个药的疗效,因为最终结果往往有多种可能的答案,可以归纳为下列三大类的情况。 1)A药和B药的疗效相同或不同,但两个药的疗效差异与是否患糖尿病无关。 2)无糖尿病的患者而言,两个药的疗效相同,对于糖尿病患者而言,两种药物的疗效不同。 3)对于糖尿病患者而言,两种药物的疗效相同,无糖尿病的患者而言,两个药的疗效不同。 如果资料符合方差分析的条件,可以用两因素方差分析进行统计分析,方差分析中的交互作用概念正是反映了上述第2种和第3种答案,即:交互作用是指某个因素对效应指标的作用与另一个因素处于何种水平状态有关(本例中治疗方案因素对疗效的作用与患者是否患糖尿病有关)。因此如果本例中治疗方案因素对疗效的作用与患者是否患糖尿病无关,则称治疗方案与是否患糖尿病对效应指标(降低总胆固醇)没有交互作用。 先考虑无交互作用的方差分析模型如下: 糖尿病的高血脂患者用B药治疗一个疗程后,总胆固醇平均下降μ(mmol/L), 糖尿病的高血脂患者用A药治疗一个疗程后,总胆固醇平均下降μ+β1(mmol/L),即糖尿病的高血脂患者用A药和用B药治疗一个疗程,两种药的疗效:总胆固醇下降幅度的平均差异为β1(mmol/L); 无糖尿病的高血脂患者用B药治疗一个疗程后,总胆固醇平均下降μ+β2(mmol/L),即同样用B药,有糖尿病的高血脂患者和无糖尿病的高血脂患者的总胆固醇下降幅度平均相差β2(mmol/L); 无糖尿病的高血脂患者用A药治疗一个疗程后,总胆固醇平均下降μ+β1+β2(mmol/L),即同样用A药,有糖尿病的高血脂患者和无糖尿病的高血脂患者的总胆固醇下降幅度平均相差β2(mmol/L)。 第10章 方差分析与试验设计 三、选择题 1.方差分析的主要目的是判断 ( )。 A. 各总体是否存在方差 B. 各样本数据之间是否有显著差异 C. 分类型自变量对数值型因变量的影响是否显著 D. 分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是 ( )。 A. 组间平方和除以组内平方和 B. 组间均方除以组内均方 C. 组间平方除以总平方和 D. 组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为 ( )。 A. 随机误差 B. 非随机误差 C. 系统误差 D. 非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为 ( )。 A. 组内误差 B. 组间误差 C. 组内平方 D. 组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 6.组内误差是衡量某一水平下样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定 ( )。 A. 每个总体都服从正态分布 B. 各总体的方差相等 C. 观测值是独立的 D. 各总体的方差等于0 8.在方差分析中,所提出的原假设是210:μμ=H = ···=k μ,备择假设是( ) A. ≠≠H 211:μμ···k μ≠ B. >>H 211:μμ···k μ> C. < 第八章 常用试验设计的方差分析 8.1 多因素随机区组试验和单因素随机区组试验的分析方法有何异同?多因素随机区组试验处理项的自由度和平方和如何分解?怎样计算和测验因素效应和互作的显著性,正确地进行水平选优和组合选优? 8.2 裂区试验和多因素随机区组试验的统计分析方法有何异同?在裂区试验中误差E a 和E b 是如何计算的,各具什么意义?如何估计裂区试验中的缺区?裂区试验的线性模型是什么? 8.3 有一大豆试验,A 因素为品种,有A 1、A 2、A 3、A 4 4个水平,B 因素为播期,有B 1、B 2、B 3 3个水平,随机区组设计,重复3次,小区计产面积25平方米,其田间排列和产量(kg )如下图,试作分析。 区组Ⅰ 区组Ⅱ 区组Ⅲ [答案: e MS 0.31,F 测验:品种、播期极显著,品种×播期不显著] 8.4 有一小麦裂区试验,主区因素A ,分A1(深耕)、A2(浅)两水平,副区因素B ,分B1(多肥)、B2(少肥)两水平,重复3次,小区计产面积15平方米,其田间排列和产量(假设数字)如下图,试作分析。 区组Ⅰ 区组Ⅱ 区组Ⅲ [答案: a E MS =0.58, b E MS =2.50,F 测验:A 和B 皆显著,A ×B 不显著] 8.5 设若上题小麦耕深与施肥量试验为条区设计,田间排列和产量将相应如下图,试作分 析,并与裂区设计结果相比较)。 B 1 B 1B 2 B 2 B 2B 1 [答案: A E MS =0.58, B E MS =1.75, c E MS =3.25,F 测验A 、B 均显著,A ×B 不显著] 8.6 江苏省淮南地区夏大豆区域试验部分资料摘录如下: 试点 年份 区组 CK 19—15 31—15 4—1 21—16 试点1 1977年 Ⅰ 134 160 168 226 196 Ⅱ 146 180 156 170 190 Ⅲ 148 206 188 216 200 1978年 Ⅰ 220 264 280 212 168 Ⅱ 228 260 276 208 156 Ⅲ 208 220 300 260 148 试点2 1977年 Ⅰ 137 236 197 196 155 Ⅱ 173 207 178 192 179 Ⅲ 110 171 223 208 125 1978年 Ⅰ 179 201 150 195 186 Ⅱ 182 224 189 203 191 Ⅲ 207 262 187 210 183 各年各点均为随机区组设计,试分析此试验结果。 [答案: 2 =3.67,e MS =406.06,Fv=12.89,Fvs=1.88,Fvy=5.18,Fvsy=10.35] 8.7 在药物处理大豆种子试验中,使用了大中小三种类型种子,分别用五种浓度、两种处理时间进行试验处理,播种后45天对每种各取两个样本,每个样本取10株测定其干物重,求其平均数,结果如下表。试进行方差分析。 处理时间A 种子类型C 浓度B B 1(0×10-6) B 2(10×10-6) B 3(20×10-6) B 4(30×10-6) B 5(40×10-6) A 1(12小时) C 1(小粒) 7.0 12.8 22.0 21.3 24.4 6.5 11.4 21.8 20.3 23.2 C 2(中粒) 13.5 13.2 20.4 19.0 24.6 13.8 14.2 21.4 19.6 23.8 C 3(大粒) 10.7 12.4 22.6 21.3 24.5 10.3 13.2 21.8 22.4 24.2 A 2(24小时) C 1(小粒) 3.6 10.7 4.7 12.4 13.6 1.5 8.8 3.4 10.5 13.7 试验设计与数据分析 1.方差分析在科学研究中有何意义?如何进行平方和与自由度的分解?如何进行F检验和多重比较? (1)方差分析的意义 方差分析,又称变量分析,其实质是关于观察值变异原因的数量分析,是科学研究的重要工具。方差分析得最大公用在于:a. 它能将引起变异的多种因素的各自作用一一剖析出来,做出量的估计,进而辨明哪些因素起主要作用,哪些因素起次要作用。 b. 它能充分利用资料提供的信息将试验中由于偶然因素造成的随机误差无偏地估计出来,从而大大提高了对实验结果分析的精确性,为统计假设的可靠性提供了科学的理论依据。 (2)平方和及自由度的分解 方差分析之所以能将试验数据的总变异分解成各种因素所引起的相应变异,是根据总平方和与总自由度的可分解性而实现的。 (3)F检验和多重比较 ① F检验的目的在于,推断处理间的差异是否存在,检验某项变异原因的效应方差是否为零。实际进行F检验时,是将由试验资料算得 的F 值与根据df 1=df t (分子均方的自由度)、df 2=df e (分母均方的自由度)查附表4(F 值表)所得的临界F 值(F 0.05(df1,df2)和F 0.01(df1,df2))相比较做出统计判断。若F< F 0.05(df1,df2),即P>0.05,不能否定H 0,可认为各处理间差异不显著;若F 0.05(df1,df2)≤F <F 0.01(df1,df2),即0.01 第六章 方差分析与正交试验设计 在生产实践和科学研究中,经常要分析各种因素对试验指标是否有显著的影响。例如,工业生产中,需要研究各种不同的配料方案对生产出的产品的质量有无显著差异,从中筛选出较好的原料配方;农业生产中,为了提高农作物的产量,需要考察不同的种子、不同数量的肥料对农作物产量的影响,并从中确定最适宜该地区种植的农作物品种和施肥数量。 要解决诸如上述问题,一方面需要设计一个试验,使其充分反映各因素的作用,并力求试验次数尽可能少,以便节省各种资源和成本;另一方面就是要对试验结果数据进行合理的分析,以便确定各因素对试验指标的影响程度。 §6.1 单因素方差分析 仅考虑一个因素A 对试验指标有无显著影响,可以让A 取r 个水平:r A A A ,,,21 ,在水平i A 下进行i n 次试验,称为单因素试验,试验结果观测数据ij x 列于下表: 并设在水平i A 下的数据i in i i x x x ,,21来自总体),(~2 i i N X ,),,2,1(r i 。 检验如下假设: r H 210:, r H ,,,:211 不全相等 检验统计量为 ),1(~) /() 1/(r n r F r n S r S F e A 其中2 1 2 11)()(x x n x x S i r i i r i n j i A i ,称为组间差平方和。 211 )(i r i n j ij e x x S i ,称为组内差平方和。 这里 r i i n n 1 , i n j ij i i x n x 1 1 , r i n j ij i x n x 111。 对于给定的显著性水平)05.001.0(或 ,如果),1(r n r F F ,则拒绝0H ,即认为因素A 对试验指标有显著影响。 实际计算时,可事先对原始数据作如下处理: b a x x ij ij 再进行计算,不会影响F 值的大小。 例1 试分析三种不同的菌型对小白鼠的平均存活日数影响是否显著? 解:30,11,9,10,3321 n n n n r 16.6,27.7,22.7,4321 x x x x 43.70)()(21 2 11 x x n x x S i r i i r i n j i A i , 74.137)(211 i r i n j ij e x x S i 49.5)27,2(90.601.0 F F ,说明三种不同菌型的伤寒病菌对小白鼠的平均存活日数的影响高度显著。 §6.2 双因素方差分析 同时考察两个因素A 和B 对试验指标有无显著影响,可以让A 取r 个水平: r A A A ,,,21 ,让B 取s 个水平:s B B B ,,,21 ,在各种水平配合),(j i B A 下进行试验, 称为双因素试验。 一、无交互作用的双因素方差分析 在每一种水平配合),(j i B A 下作一次试验,称为无交互作用的双因素试验,试验结果观测数据ij x 列于下表: 实验设计与分析课程论文 题目利用SPSS 软件进行方差分析和正交试验设计 学院 专业 年级 学号 姓名 2012年6月29日 一、SPSS 简介 SPSS 是世界上最早的统计分析软件,1984年SPSS 总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS 微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域,世界上许多有影响的报刊杂志纷纷就SPSS 的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价与称赞。 SPSS 的基本功能包括数据管理、统计分析、图表分析、输出管理等等。SPSS 统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类,每类中又分好几个统计过程,比如回归分析中又分线性回归分析、曲线估计、Logistic 回归、Probit 回归、加权估计、两阶段最小二乘法、非线性回归等多个统计过程,而且每个过程中又允许用户选择不同的方法及参数。SPSS 也有专门的绘图系统,可以根据数据绘制各种图形。SPSS 的分析结果清晰、直观、易学易用,而且可以直接读取EXCEL 及DBF 数据文件,现已推广到多种各种操作系统的计算机上,它和SAS 、BMDP 并称为国际上最有影响的三大统计软件。 SPSS 输出结果虽然漂亮,但不能为WORD 等常用文字处理软件直接打开,只能采用拷贝、粘贴的方式加以交互。这可以说是SPSS 软件的缺陷。 二、方差分析 例如 某高原研究组将籍贯相同、年龄相同、身高体重接近的30名新战士随机分为三组,甲组为对照组,按常规训练,乙组为锻炼组,每天除常规训练外,接受中速长跑与健身操锻炼,丙组为药物组,除常规训练外,服用抗疲劳药物,一月后测定第一秒用力肺活量(L),结果见表。试比较三组第一秒用力肺活量有无差别。对照组为组一,锻炼组为组二,药物组为组三。 第一步:打开 SPSS 软件 表1 三组战士的第一秒用力肺活量(L) 对照组 锻炼组 药物组 合计 3.25 3.66 3.44 3.32 3.64 3.62 3.29 3.48 3.48 3.34 3.64 3.36 3.16 3.48 3.52 3.64 3.20 3.60 3.60 3.62 3.32 3.28 3.56 3.44 3.52 3.44 3.16 3.26 3.82 3.28 第10章方差分析与试验设计 三、选择题 1.C 2.B 3.A 4.B 5.C 1.方差分析的主要目的是判断()。 A.各总体是否存在方差 B.各样本数据之间是否有显著差异 C.分类型自变量对数值型因变量的影响是否显著 D.分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是()。 A.组间平方和除以组内平方和B.组间均方除以组内均方 C.组间平方除以总平方和D.组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为()。 A.随机误差B.非随机误差C.系统误差D.非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为()。 A.组内误差B.组间误差C.组内平方D.组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它()。 A.只包括随机误差 B.只包括系统误差 C.既包括随机误差,也包括系统误差 D.有时包括随机误差,有时包括系统误差 6.A 7.D8.D9.A10.A 6.组内误差是衡量某一水平下样本数据之间的误差,它()。 A.只包括随机误差 B.只包括系统误差 C.既包括随机误差,也包括系统误差 D.有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定()。 A.每个总体都服从正态分布B.各总体的方差相等 C.观测值是独立的D.各总体的方差等于0 8.在方差分析中,所提出的原假设是0:=···= ,备择假设是() 12 k A.1:12···kB.1:12···k C. 1:···kD.1:1,2,···,k不全相等 12 9.单因素方差分析是指只涉及()。 A.一个分类型自变量B.一个数值型自变量 C.两个分类型自变量D.两个数值型因变量 10.双因素方差分析涉及()。 A.两个分类型自变量B.两个数值型自变量 C.两个分类型因变量D.两个数值型因变量 11.B12.C 第16章随机区组设计和析因设计资料的分析 思考与练习参考答案 一、选择题 1.对于随机区组设计资料,应用单因素方差分析与用随机区组方差分析的结果相比,( A )。 A. 两种方法适用的资料不同而不可比 B. 检验效果不能确定 C. 两种方法都可以用 D. 两种方法检验效果相同 E. 以上均不对 2.在某项实验中欲研究A、B两因素对某观测指标的影响,A、B两因素分别有2个和3个水平,观测指标为数值型变量,假设检验的方法应选用( D )。 A. 随机区组设计资料的方差分析 B. 析因设计资料的方差分析 C. Friedman检验 D. 根据设计类型、资料分布类型、变异情况和研究目的等选择的检验方法。 E. 以上均不对 3. 与完全随机设计及其方差分析相比,随机区组设计及其方差分析可以使其( A )。 A. 变异来源比前者更多 B. 误差一定小于前者 C. 前者的效率高于后者 D. 影响因素的效果得到分析 E. 以上说法都不对 4.下面说法中不正确的是( D )。 A.方差分析可以用于两个样本均数的比较 B.完全随机设计更适合实验对象的混杂影响不太大的资料 C.在随机区组设计中,每一个区组内的例数都等于处理数 D.在随机区组设计中,区组内及区组间的差异都是越小越好 E.以上均不对 5.配对t检验可用( B )来替代。 A.完全随机设计资料的方差分析 B.随机区组设计资料的方差分析 C.A、B两种方差分析都可以 D.析因设计的方差分析 E.以上都不可以 二、思考题 1.随机区组设计与完全随机设计资料在设计和分析方面有何不同? 答:在设计上,与后者比,前者在设计阶段按照一定条件将受试对象配成区组,平衡了某些因素效应对处理因素效应的影响,更好地控制了其他因素对处理因素效应的影响,设计效率较高。 1、通过以下试验设计案例总结“正交试验设计的基本程序和步骤”。 案例:为了研究啤酒酵母最适合的自溶条件,选择3因素3水平正交试验。因素有温度℃(A)和pH(B),加酶量(C)3个,试验指标为蛋白质含量,试验指标越大越好。选用L9(34) 正交表,试验方案和结果如下表,试作方差分析,并找出啤酒酵母最适合的自溶条件。 4 1、明确试验目的,确定试验指标:找出啤酒酵母最适合的自溶条件,可用蛋白质含量作为本试验的试验指标。 2挑因素,选水平:影响啤酒酵母最适合的自溶条件的因素有温度、pH和加酶量3个,分别用A、B、C表示,并且每个因素都取3个水平,因此,此次选取3因素3水平正交试验。 3、选择合适的正交表:根据所选取的实验因素和实验水平数,决定该实验选取L9(34) 正交表。 4、进行表头设计(表1-1) 表1-1 由于此试验不考察因素之间的交互作用,所以采用不考察交互作用的方差分析法进行实验结果发差分析,并且此试验无重复试验,所以采用不考察交互作用的方差分析法中的无重复试验的方差分析。结果如表1-3 本例a=b=c=3,各因素每一水平的重复次数m=3,总处理次数为9次(n). ②平方和与自由度的分解。 平方和的分解: 矫正数 C=()2 i x n ∑=2T n =65.2/9=477.8596 总平方和 SS T =2i x ∑-C=6.252+4.972+…+8.952-C =530.89-477.8596=53.0304 A 因素平方和 SS A =2iA K m ∑-C=(15.762+18.572+31.252)/3-C =523.2617-477.8596=45.4021 B 因素平方和 SS B = 2iB K m ∑-C=(25.182+21.412+18.992)/3-C =484.3469-477.8596=6.4873 C 因素平方和 SS C = 2 iC K m ∑-C=(22.652+21.452+21.482)/3-C =478.1718-477.8596=0.3122 误差平方和 SS e = SS T -SS A -SS B -SS C =53.0304-45.4021-6.4873-0.3122=0.8288 对于空列也可用同样方法计算平方和: 空列平方和 SS D =2iD K m ∑-C=(20.742+21.872+22.972)/3-C =478.6884-477.8596=0.8288 自由度的分解: 总自由度 df T =n-1=9-1=8 A 因素 df A =a-1=3-1=2 B 因素 df B =b-1=3-1=2 C 因素 df C =c-1=3-1=2 误差 df e =df T -df A -df B -df C =8-2-2-2=2 显然,误差的自由度等于各空白列自由度之和,正交表中各列的自由度为该列的水平数减1。 ③F 测验。方差分析的结果见表1-4。由方差分析的结果可知,A 因素(温度)的F 值 显著,说明A 因素对蛋白质含量有显著的影响 表1-4 方差分析表 变异来源 SS df MS F F α 试验设计与方差分析 SPSS操作 一、试验设计与方差分析的关系 试验设计并不是一种统计方法,而是一组统计方法的统称,其主要用途在于分析自变量x的值与因变量y值之间的关系。此外,还用于降低背景变量对理解x值与y值之间关系时的影响。 试验设计使用的最主要的统计工具是方差分析,因此,许多教材将试验设计与方差分析设计为同一部分,使用共同的概念和术语。 其实方差分析并不仅仅在试验设计领域使用,也可以用来分析观察数据。 二、基本术语 例:影响某温室水果产量的主要因素有三个:施肥量、浇水量、温度。如果想通过控制三个因素的量,找出一个最优组合来提高产量,就是实验设计与方差分析问题。相关的术语有: 自变量(因子、因素、输入变量、过程变量):可以控制的、影响因变量的变量。本例为施肥量、浇水量、温度。 因变量(反应变量、输出变量):我们所关心的、承载试验结果的变量。本例为产量。 背景变量(噪声、噪声变量、潜伏变量):能观察但不可控的因子或因素,影响较小、达不到自变量水平。本例可能有测量误差等。 水平(设置):自变量的不同等级。水平数通常不多,连续型变量需离散化取值。如本例:施肥设1000克、1100克、1200克三个量, 浇水量设200千克、220千克两个量,温度设18度、20度、22度三个量。 处理:各因子按设定水平的一个组合。如本例:施肥1000克、浇水200千克、温度18度为一个处理。 试验单元:试验载体的最小单位。如本例的一个温室或由一个温室分割形成的房间。 主效应与交互效应:两因子及以上试验时,各因子可能对因变量有影响,因子间的相互作用也可能对因变量有影响。于是就有了上述概念。有时,交互效应比主效应更重要。如本例:施肥固定在1000克,浇水固定在200千克,18度、20度、22度三个温度条件下产量的差异,可以理解为温度的主效应;而同一温度条件下,不同的施肥量、浇水量造成的产量差异,就是交互效应。 三、试验设计的三个基本原则 第一,随机化。即采取机会均等的措施,将各种条件完全随机地配置在试验单元上。目的是要尽量消除试验因素之外的其他因素的干扰(平衡处理,不是减少误差,而是避免某种未知因素与系统因素相混淆)。极其重要。 第二,重复(复制)。即基本试验的重复,将一个处理施于两个或两个以上试验单元。重复的目的主要在于估计误差。没有对误差的估计就无法做出试验结论。同时,重复也有助于更准确地估计因子的效应。 第三,区组化。一组同质齐性的试验单元称为区组。即对试验单正交试验设计及其方差分析
2×2析因设计资料的方差分析
第10章 方差分析与试验设计
第八章常用试验设计的方差分析
试验设计与数据分析
第六章--方差分析与正交试验设计讲解学习
利用SPSS_进行方差分析以及正交试验设计
第10章__方差分析与试验设计
第章随机区组析因设计资料的分析思考与练习参考答案
试验设计案例方差分析
实验设计与方差分析